[IQA #3] How to detect Fovea/Macular Center on retinal images
This post follows the [IQA #2], and we will be discussing approaches to detect fovea on retinal images, using image processing techniques.
For today’s post, we will be discussing possible ways to detect fovea/macular center on retinal images, exploring possible approaches based on image processing, segmentation and object detection.
Note that, the fovea is the structure present on the center of the macula, so finding the whole macula may be an interesting way to detecting the fovea or macular center. We need to detect this structure on retinal images to solve another Image Field parameter: “2. The macular center is at least 2 DD from the temporal edge”.
From the last post, we are already able to find a great approximation for the DD measure. We have used that to find the distance between the optic disc and the nasal edge; now, consider that, if the nasal edge is the closest retinal edge to the optic disc, the temporal edge is the further one.
Why avoid using object detection
Lack of data! It seems like such a simple answer, and it actually is. In order to detect the optic disc on retinal images, we have used 6 different datasets, that somehow had annotations based on the optic disc, that being segmentation masks, annotations on the image itself or the actual bounding boxes coordinates to perform object detection.
With that in mind, our first approach was trying to apply the same techniques on the macular center, but when looking for data focusing on localizing the fovea/macula, we were not able to find datasets great enough to be used. The IDRID dataset had annotations for the macula, but they consisted only on the central point, so we had to analyze individually the images, in order to get nice bounding boxes and train a model. The REFUGE2 dataset also seems to have annotations, but the competition where the dataset dropped has closed in 2020, and I got no replies when trying to get the dataset.
After trying everything to keep that in mind, we do not simply avoid using object detection, but if we are going to use a system like that, we need to make sure to get a nice dataset, where this technique can be applied. But how are we going to access this data?
Applying image processing on retinal images
If you wish to take some attention on retinal images, you will notice that, not only the optic disc is the brightest part of the retinal image, but also the macula is the darkest region (alongside the blood vessels). That way, we can use that information to try and apply some image processing and see what kind of information we can get on the image, and check if that helps us find the fovea.
Flying alway from theoretical thoughts and going towards what should actually work, when looking for authors who had performed that to detect the fovea, we came across an interesting article called Appearance-based object detection in colour retinal images. On this article, the authors get nice results detecting the fovea based on image processing techniques, assuming that the region is visible and is, indeed, darker than the other structures.
The whole idea is based on the fact that the darkest regions are not as visible as you would’ve expected on the red color channel. With that, we can apply some transformations in order to try and isolate the region. We have also decided to apply a mean filter on the image, in order to remove “noisy points” from the thresholded image.
Image transformations
First of all, we load the original image in grayscale, and separate the red channel:
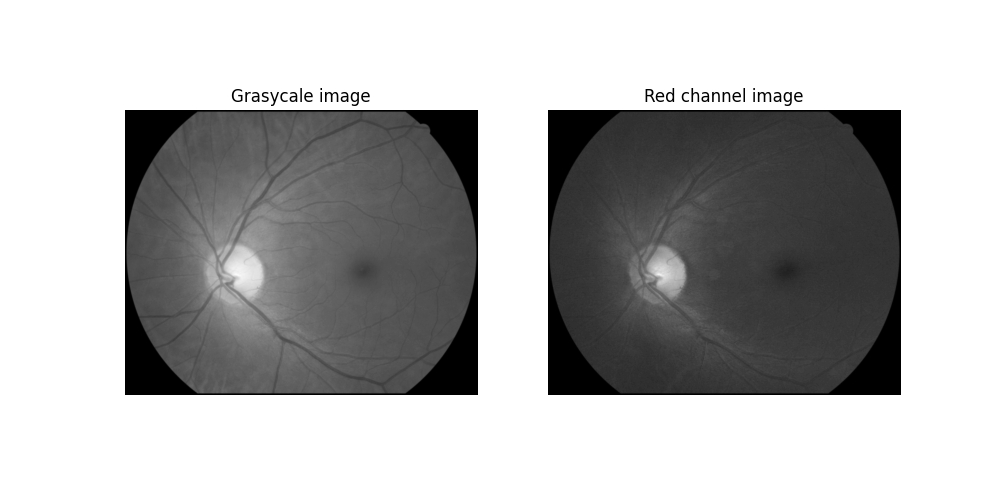 Grayscale and red channel image
Grayscale and red channel image
With that done, now we want the darker regions to be visible on the image. We use cv2.equalizeHist function from Python OpenCV, in order to enhance contrast on both images, obtaining I_A and I_B. The results can be seen on the next image
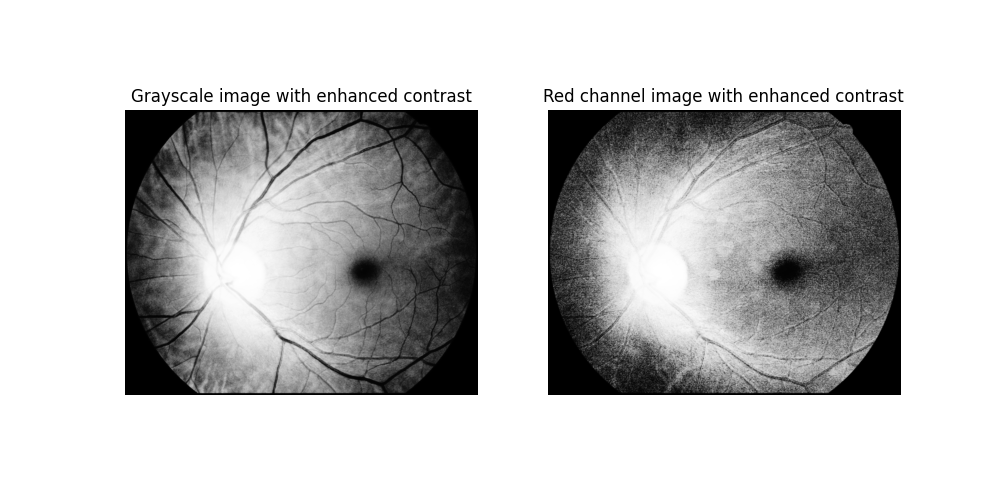 Contrasted grayscale and red channel image
Contrasted grayscale and red channel image
Now, we want to get the complement of the red channel image:
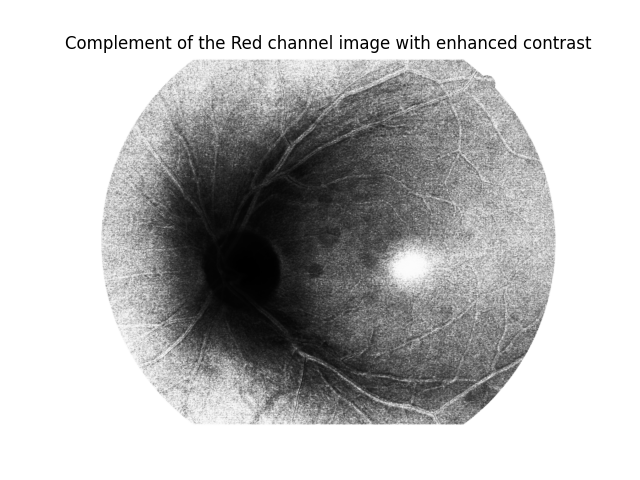 Complement of the red channel image
Complement of the red channel image
On the paper, the authors states that, after getting the complement, the darker regions just grow a lot, so they apply a Top Hat operation in order to diminute that. We have applied a Top Hat with kernel size (1,1) on the red channel image. We chose that kernel size because it had the best results on this specific image, but the resultant image was fully black. From that, we subtract the top-hatted image from I_A, and apply the mean filter, in order to remove noise:
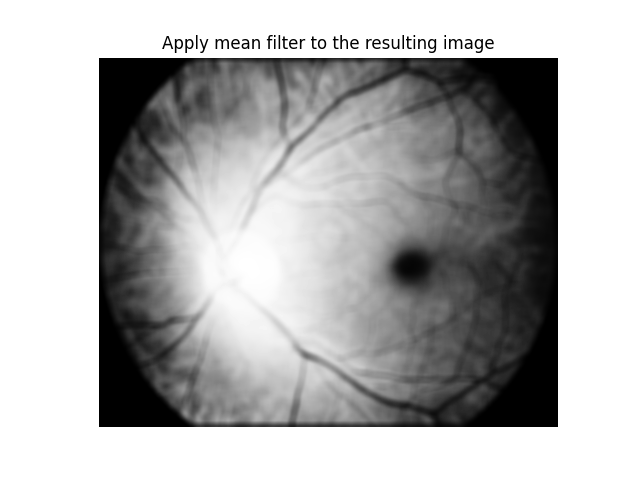 Mean-filtered top-hatted subtraction image
Mean-filtered top-hatted subtraction image
With all that done, you can observe that the fovea is really visible on the image. Now, what we want to do is fully separate it from the rest of the retinal structures. A way to do that is using a threshold function _, thresh = cv2.threshold(I_s, 15, 255, cv2.THRESH_BINARY) where thresh is a result matrix from the image, after applying the threshold 15, i.e., all the pixels with value lower than 15 are turned into black, and the remaining ones are turned into white. With that, we get a fovea segmented image:
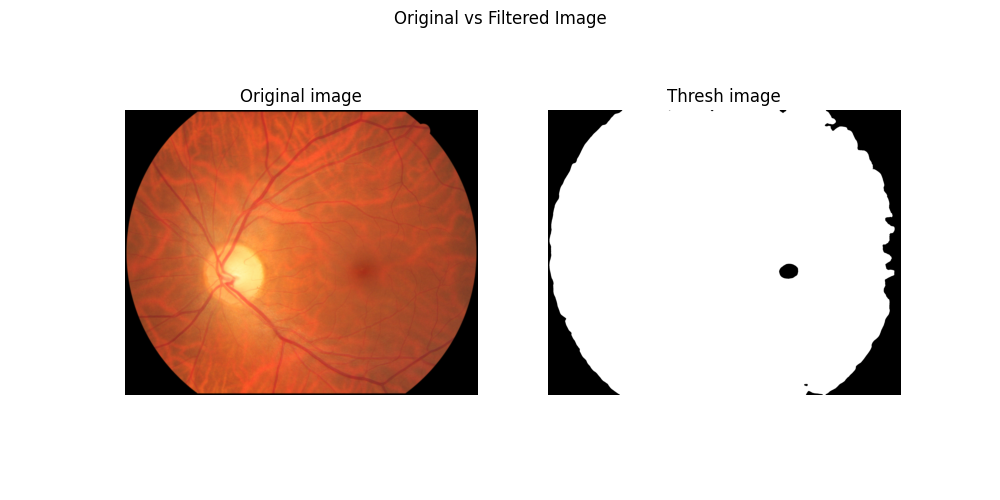 Fovea segmentation after transforms
Fovea segmentation after transforms
Final adjusts
The overall result seems to be fine and this may be used to solve our second parameter for the Image Field definition, but the image still lacks some adjustments. For instance, it is way more interesting for us to have an image where the fovea is the only segmented part of the image, in order to apply our algorithm to extract a bounding box from the segmented image.
Knowing that, I had no idea on how to remove the background regions and noises that are also part of the problem we were facing. My only guess was to use connected components, but not being sure on how to do so without hard coding it, adapting a DFS for the task, which would’ve worked had I known how to proceed from that. So, for the sake of time saving, I recurred to a LLM model to help me code that, and the model has recommended the use of cv2.connectedComponentsWithStats. That function actually calculates the connected components from an image and attributes labels to it and the coordinate for the center of each component.
With that done, what the LLM recommended was to iterate through the components, get the center coordinate from it and calculate the distance from the image center to the center of the component. Theoretically, the closest component to the image center should be the fovea. Another approach used was to consider the component area, and discard every component with an area smaller than 30, to avoid possible noisy components.
Now, we are able to just apply a mask based on the target component (closest to the image center, with an area greater or equal 30) and check the results.
 Final Fovea segmentation
Final Fovea segmentation
Possible problems and conclusion
We have not performed tests for other images yet. You can see that, in the segmentation comparison image, the fovea on the original image was not clearly visible and became visible with our segmentation method. Yet, we still need to see how the processing will perform with images with a worst fovea visibility, and also if the segmentation method will segment other dark structures in other input images, like blood vessels or diseases spots. We were already able to vanish the blood vessels by using the top hat transformation with a lower kernel size.
After all that is discussed, I still do not think applying this should be the best resolution for this problem, for the motives I have just stated. But, if we are able to apply that and it works fine for a lot of images, we can get a dataset from segmented images, and perform a object detection task on this dataset. That way, we do not depend on images resolution, colors and structure, but only on the generalization of a machine learning model.
I will be bringing those thoughts into consideration and talking about it with my advisor, in order to see if any of that actually makes sense. If it does, the next post will be about the training of the YOLO model and finding the distance between the macular center to the temporal edge. If not, we will probably be heading to the final goal in this project in order to solve the Image Field quality problem.
Next Steps
From what we have seen on the last topic, the optic disc detection may still face some issues, that will further be analyzed and reviewed, in order to see if it is necessary to refactor the code in any parts. But, for now, the results seem to be working as expected, and were approved by my advisor.
- Understanding and studying the problem
- Choosing dataset
- Preprocessing data
- Define training baseline
- Applying YOLO to detect Optic Disc (OD)
- Obtaining the disc diameter (DD)
- Obtaining distance from the OD to the Nasal Edge
- Detect Macular Center
- Obtaining the distance from the Macular Center to the Temporal Edge
- Assessing visibility for the inferior and superior arcades
This post is used as a research checkpoint for the image quality assessment research on retinal fundus images, supervised by professor Nina S. T. Hirata, from the Institute of Mathematics and Statistics at the University of São Paulo (IME USP). The project is supported by USP/MCTI/Softex/Motorola.