Implementing MetaOptNet for Retinal Fundus images
For the past year, I have been working with a dataset called Brazilian Multilabel Ophthalmological Dataset (BRSET). This dataset was first developed at the Federal University of São Paulo, by medical researchers, and has around 16.266 images of Retinal Fundus, all with tones of annotations, available at a .csv file. The main problems that can be worked with this dataset are disease classification, with 13 different classes of diseases, and the image quality assessment, which is the main problem I have been trying to solve. In this post, we are focusing at the disease classification problem.
Problem origin
It is important to start by talking about how the problem came ahead for us. My advisor was contacted by some doctors from the University of São Paulo Medical School (FMUSP), by the end of 2023, when were starting this one project to analyze possible causes to cognitive deviation, and one of their main lines of research was trying to relate it to diabetes. It turns out that, diabetes is easily recognizable from retinal images.
You may be thinking now: there is a lot of projects that are focusing only on extracting diabetic retinopathy (DR) from retinal images, and that is true, but those doctors want to take this project further and gather data from portable retinographs, that can be used in public hospitals in Brasil, and help diagnosing DR early. That is when our project comes. Why not extend all of this to more retinal diseases and train a classifier to do that?
As one may imagine, gathering data for most of diseases is pretty difficult, some diseases may be really rare, some pacients may not want to disclosure their retinal pictures (even though it does not apparently invades their privacy), and deep learning actually needs a lot of data. Some images may even have bad quality, or else we would not be assuming a quality assessment task as well. With that in mind, Gabriel J. Perin, a fellow student at IME-USP, started his undergraduate research project with the BRSet dataset, exploring few-shot learning techniques to train a classifier for this problem, which we will further talk more about.
Perin’s paper describes how he handled the data selection up to the models he tested, and got to achieve some better results for few-shot learning techniques in some cases. At an event my advisor held at the institute, he came to the group with an idea to add more information to that paper, and hopefully find some other things to publish. We gathered around some groups, and I felt like I could help with expanding the few-shot techniques explored, that were, back then, limited by only the Reptile algorithm. In this post, I will be talking about the MetaOptNet algorithm, that I have implemented to help getting new results for this research.
About meta learning and few-shot learning (FSL)
Meta Learning is the idea of “learning to learn”, and was adapted to Machine Learning as scientists would stumble upon problems with only few examples per class. By that, you can think that meta learning and few-shot learning actually hold hands and walk together as concepts in machine learning, and if you thought that, you are right. If you think this post is where you are going to learn about those concepts, I suggest that you actually stop right here and go read a paper, that covers this better, since I will be just talking about basic things needed to understand the algorithm.
For FSL we have a simmilar but different goal than normal machine learning classification problems. Our model is responsible for learning from tasks T for training, and be evaluated on T’ for testing, optimizing our parameters on the meta-training dataset. You can think that, for each training task, we have a differente dataset D, that we want to optimize our model. So let N be the number of classes available at a task, and K be the number of examples per class on a task, we call a few-shot learning task as a N-way K-shot task.
In this problem abstraction, the real beauty is that we only train our model with limited number of classes, sampled from all the classes, and, when testing the model, we use a dataset that does not contain any of the classes that the model has seen previously during training. So, before training, we separate some classes only for testing, and for the remaining classes, on each task, we sample K examples from N classes to fill in our model training. Every training epochs runs for a certain number of episodes, which represents all the tasks. After training is done, we can see if our model is generalizing well to classify classes it has never seen before.
Some basic names we should be familiar with are the support set, given as the training examples for a N-way K-shot task, the query set, used to evaluate the model during training. This is a validation set, and has the exact same classes as the support set. Last, but not least, we have the test set, used to evaluate the model after training, and has no classes intersecting the set of classes from the previews sets.
The MetaOptNet implementation
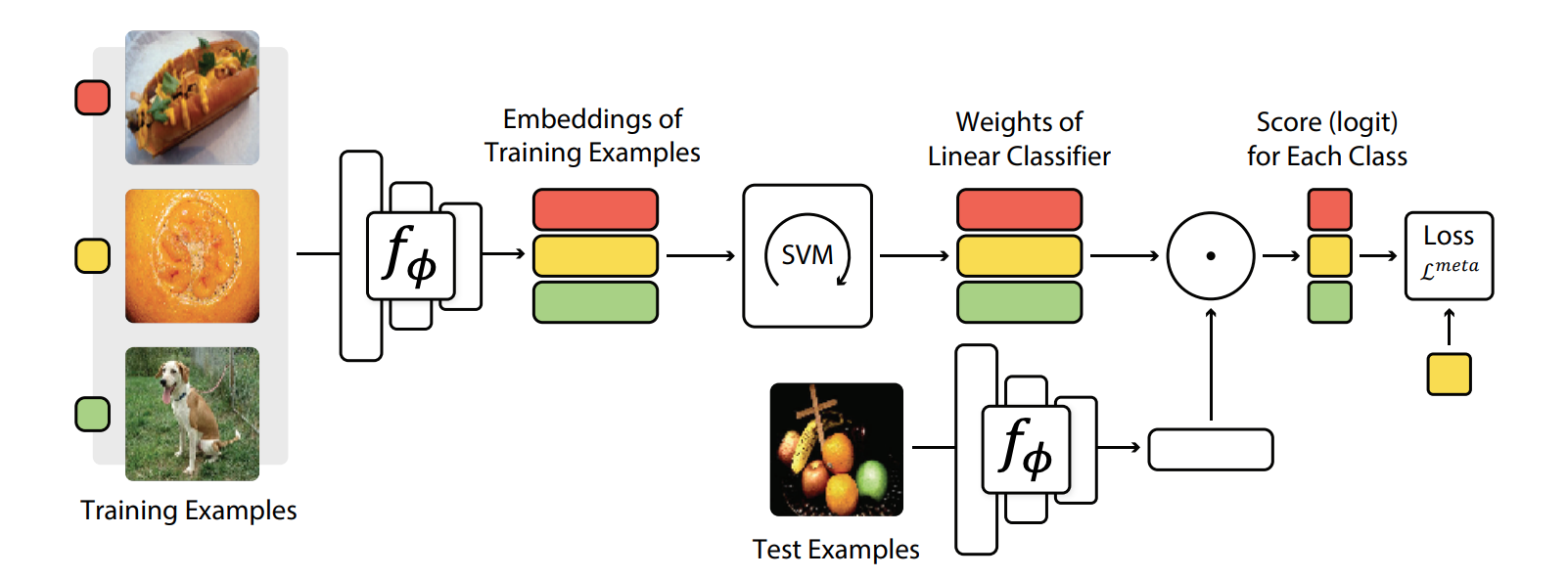 MetaOptNet visual representation.
MetaOptNet visual representation.
I will not be disclosing much about the MetaOptNet functionality, its paper was already cited above and can be read by those who are interest in. Basically, our group is developing methods trying to keep the main structure Perin has already developed for data selection and training. In order to do so, we need to adapt the classification part of the network, and test the results with different data embedding models, such as ResNet50, Swin and Vit, for this project.
In order to get nice results, and keeping things clean, a fellow student has developed a training algorithm that uses Perin’s data manager, in order to create a standard training routine for few-shot learning methods. That routine works pretty good, but some things may need to be altered, depending on how you are implementing the methods. For me, I chose to get the original code from the MetaOptNet training and see how they implemented training for that network. For our personal project, most of the training code was simmilar to what we needed, so I kept the same structure, and took the code for the SVM classifier the authors have used. The authors also keep some embedding networks available at their code, but none of those were the same as the ones we were interested, and, in order to keep things flowing the right way, and test all the models with the same initial weights for feature extractors I decided to keep using the backbones from timm.
With that done, all there is left to do is training the model. For that, we run the sampled input images for each task on the timm model, and run the embedding obtained through the classification head, obtained from the original MetaOptNet code. That way, all there is left to do is evaluate the model.
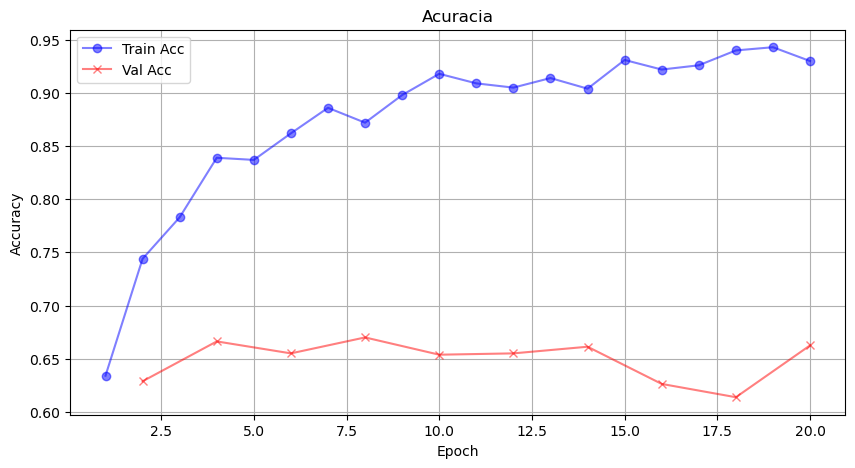 MetaOptNet training accuracy evolution.
MetaOptNet training accuracy evolution.
For now, the only test we ran for this model was for 2-way 5-shot tasks, which got a 62% accuracy result for the Reptile model. From our accuracy evolution plot, we can see that getting a better accuracy was not really a problem. As for right now, we are keeping the model trained like this, but we will be refactoring the code and running tests for other tasks, and testing other parameters. Notice that the parameters may be changed, because we do not get to see an actual accuracy evolution throughout the epochs. With that said, this page will be updated in the near future!